Every procurement leader we talk to is thinking about the same thing right now: AI agents.
Not chatbots. Not dashboards with AI sprinkled on top. Actual autonomous systems that can open a PO, match an invoice, flag a contract discrepancy, and push a payment through, without a human toggling between six browser tabs.
The appeal is obvious. McKinsey projects that agentic AI could make procurement functions 25 to 40% more efficient. 90% of procurement leaders say they're implementing or planning to implement AI agents in the next twelve months.
But a lot of companies hear "agents" and immediately think: we should build this ourselves. We have engineers. We have data. We know our own systems. How hard could it be?
The problem isn't ambition. It's that the gap between a procurement agent that works in a demo and one that works in production is enormous, and the failure modes are expensive enough to set a program back years.
Where in-house builds run into trouble
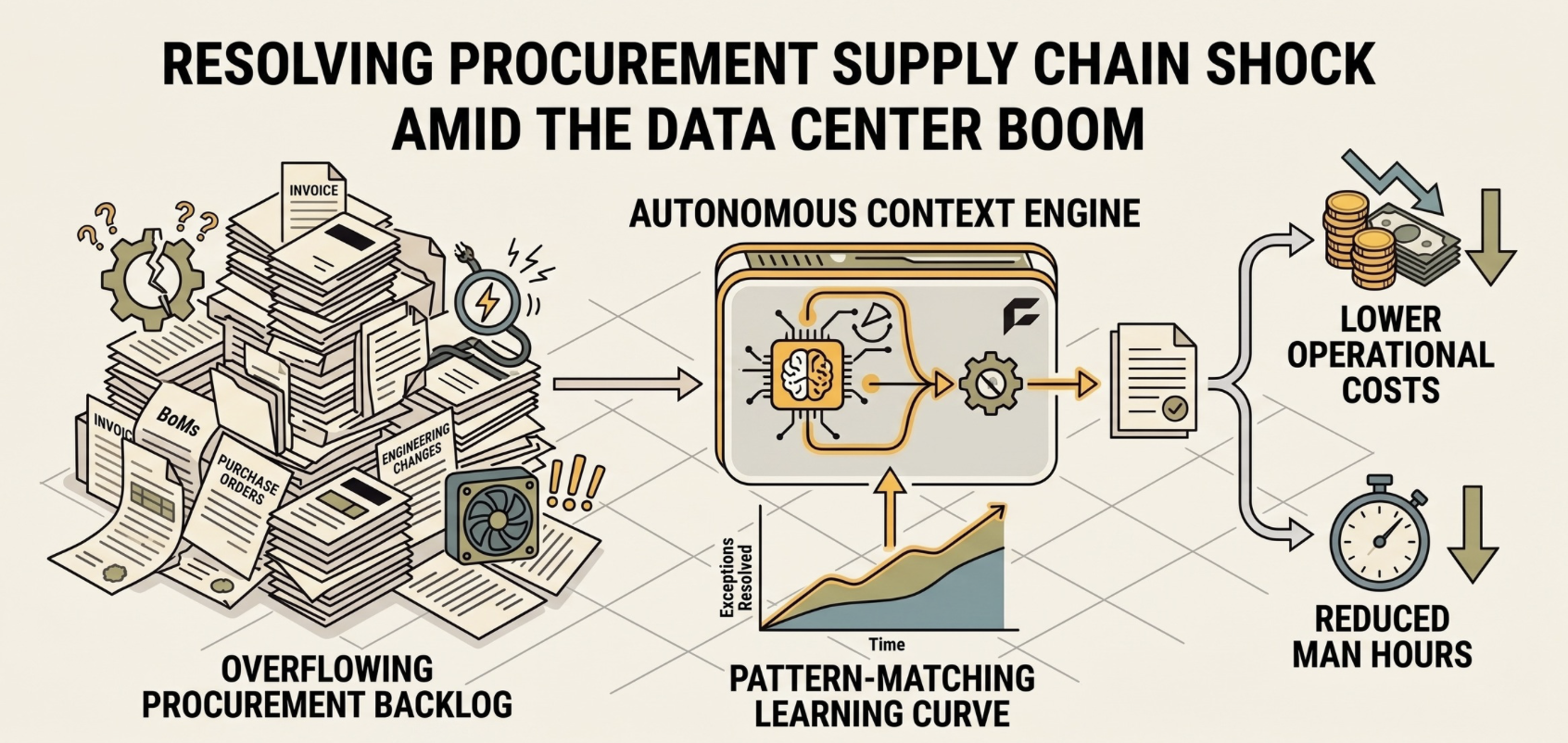
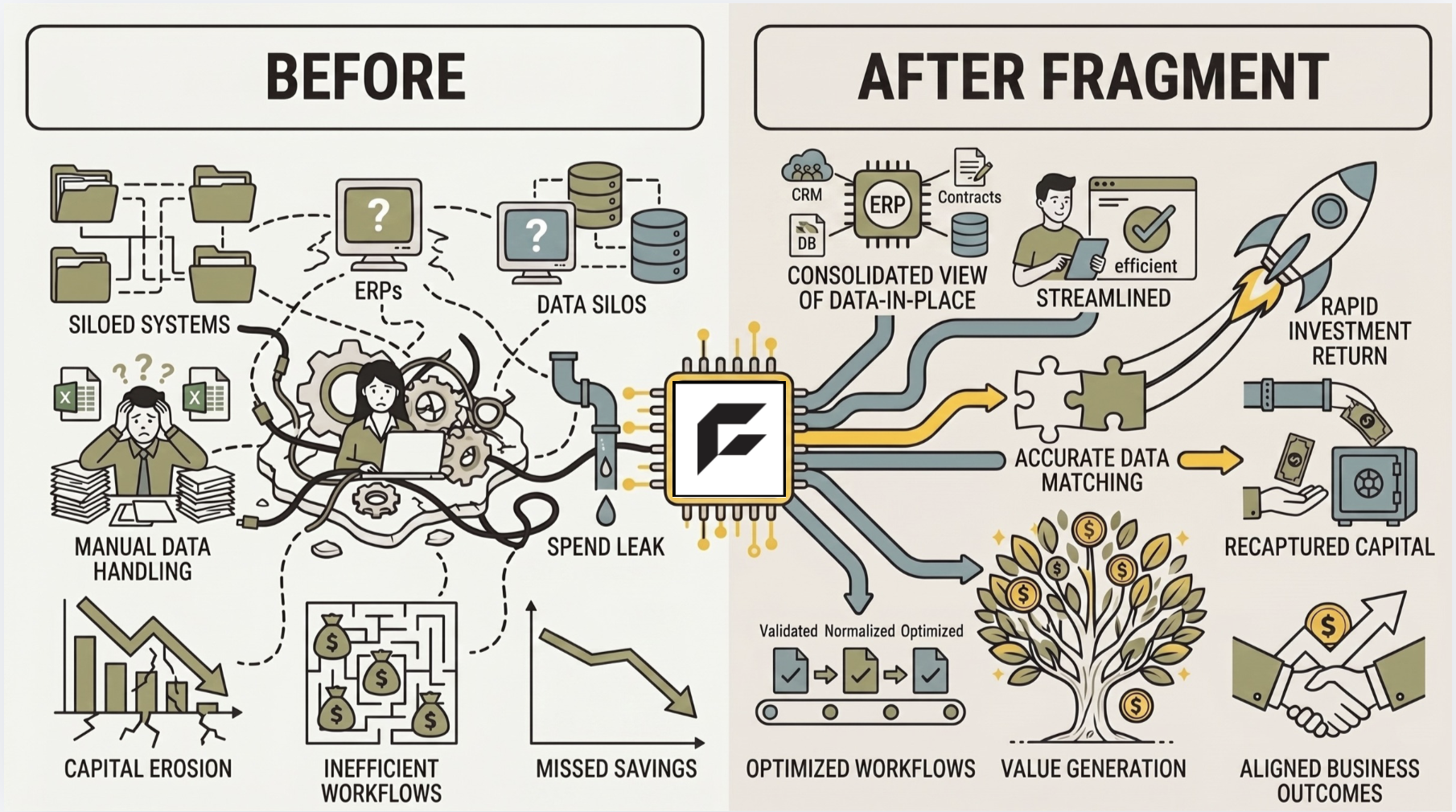
Your tech stack is siloed, and your agent inherits every silo. Procurement data doesn't live in one system. It's scattered across your ERP, CLM, supplier portals, email threads, chat logs, and spreadsheets. An agent that reads a PO in SAP but can't cross-reference contract terms in your CLM, or check delivery history in a supplier portal, is just a faster way to produce wrong answers.
Deloitte's Global CPO Survey found that 57% of procurement leaders point to siloed structures as a major obstacle to delivering value. 47% of business leaders cite integration complexity as the biggest barrier to ROI on new technology. When you build agents on top of a fragmented tech stack, you inherit all of it. Most in-house projects end up automating a single step while leaving the rest of the workflow untouched.
The real knowledge isn't just in your structured data. It's buried in emails, chat threads, and years of undocumented decisions. The hard part isn't connecting to systems. It's teaching the agent that the supplier abbreviation "JNJ-MED" maps to Johnson & Johnson Medical Devices because someone mentioned it in a Slack thread two years ago. That "Net 45" in the contract actually means "Net 30" because of an amendment from last February buried in an email. That when a three-way match fails by 2% on a particular commodity, your team approves it because the supplier always ships heavy, a pattern that lives only in how your AP team has historically handled that exception.
This is institutional knowledge. Some of it lives in people's heads, but a surprising amount of it lives in communication channels, in approval patterns, in the implicit logic of thousands of past decisions. McKinsey found that procurement functions use less than 20% of available data. The data exists. The challenge is building technology that can reason across all of it.
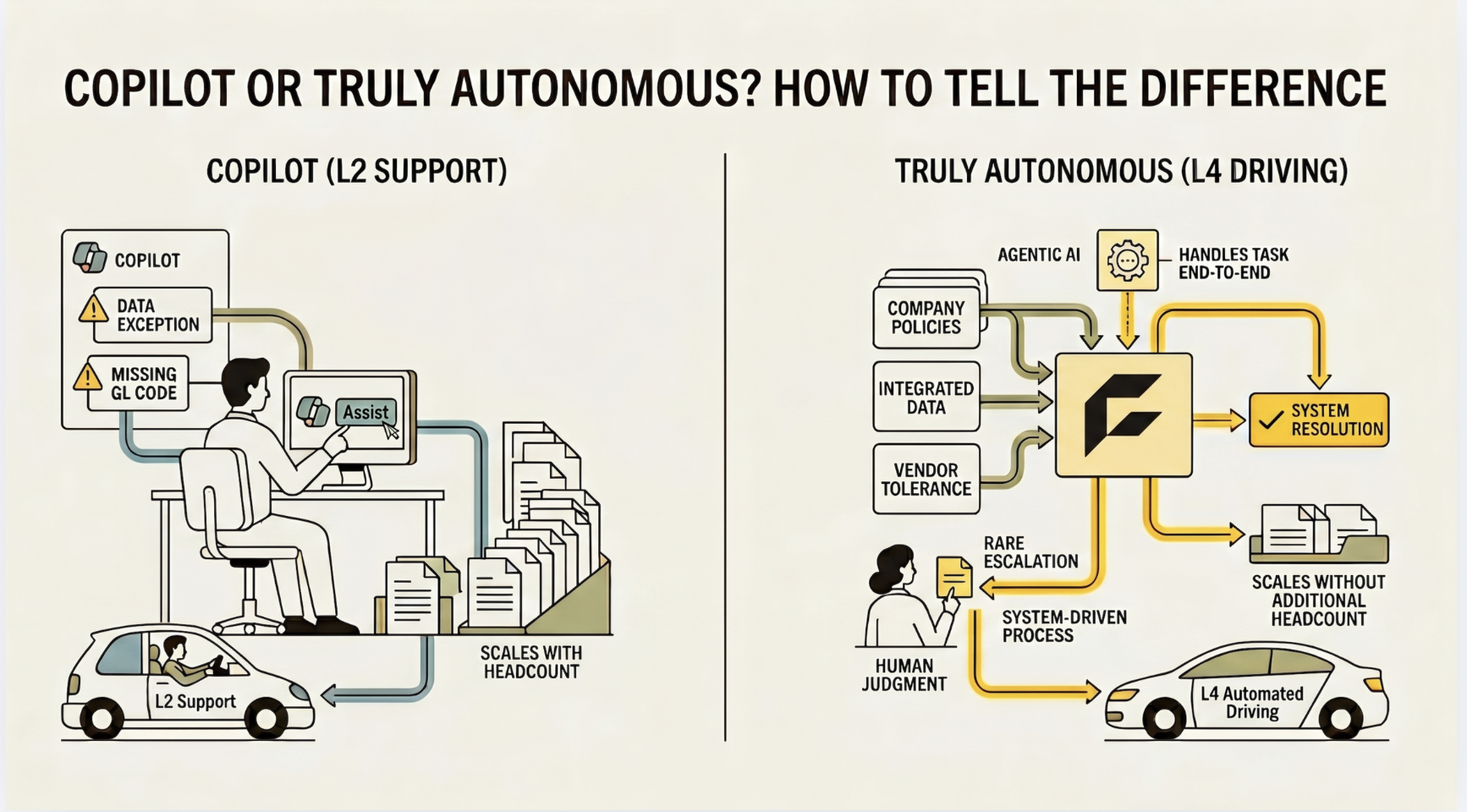
Then the brittleness problem hits. This is the failure mode that's hardest to see coming and most expensive to recover from.
In a demo, your agent resolves an invoice exception perfectly. In production, a supplier changes their invoice format. A contract gets amended. A business unit restructures and approval chains shift overnight. Suddenly your agent either halts or, worse, processes transactions incorrectly at scale.
Brittle software is a well understood problem in engineering, and brittle AI agents can be much worse. Traditional brittle software fails visibly. A brittle AI agent can fail silently, confidently pushing through incorrect matches while your team assumes it's working. Building agents that hold up when procurement actually changes, suppliers renegotiating, policies updating, org structures shifting, requires deep technical skill and hard-won experience with production AI systems. It's not an operations challenge you can power through. It's an engineering problem that takes years to solve well.
And it's expensive to learn this the hard way. Enterprise agent development runs $100,000 to $500,000+ for a multi-agent system with integrations, with maintenance adding 15 to 25% annually. 80% of enterprises underestimate their AI infrastructure costs by more than 25%.
What the right approach actually looks like
If you step back from the hype, the pattern is clear. Every failure mode above traces back to the same root cause: the agent doesn't understand the full context of the operation it's supposed to automate.
The right approach starts with a technology layer that can connect to every system in the procurement tech stack, structured and unstructured, and reason across all of it in place. Not just reading the data, but inferring the institutional knowledge embedded in it: the policies nobody wrote down, the approval patterns that emerged organically, the supplier relationships that only make sense if you can see the full history across communications and transactions.
Think about Spotify. Spotify's fundamental innovation was understanding your musical taste without being told. You didn't fill out a form listing your preferences. It inferred them from your behavior and used that understanding to surface music you didn't even know you wanted. The right procurement automation works the same way. It learns how your operation actually runs and applies that understanding consistently, so your team's best judgment is reflected in every transaction, not just the ones they have time to review manually.
We've seen this work in practice. A Fortune 500 manufacturer had a 90%+ reduction in AP labor once the system could reason across their full procurement stack, and two-thirds of the exceptions it resolved had no prior automated solution. It wasn’t that the data didn’t exist. Rather, no system had been able to connect the dots across ERPs, supplier portals, contracts, and communication history simultaneously.
That context layer is what separates agents that work in a demo from agents that work in production. When an agent can reason across the full tech stack, it can span the entire source-to-pay lifecycle instead of just automating a single step. It can reconcile exceptions independently, without waiting for a human to open six tabs and make a judgment call. And because it continuously learns which resolution strategies work, it gets more robust over time instead of more brittle.
The system still needs your team in the loop. You need the ability to tune, override, and audit what it does. But the baseline should be an agent that already understands your operation well enough to act correctly on the vast majority of transactions, because it inferred how your team has always handled them.
Ardent Partners puts the industry average invoice exception rate at 22%, and even top performers carry 9%. The technology to drive that number toward zero exists. The question is whether you build it from scratch or start with something purpose-built.
Build or buy?
Building in-house is the right call in some cases. If you're automating a well-scoped workflow inside a single system, your team controls the data model, and you have the engineering capacity to commit for 12+ months, you can build something that works.
The question is what happens when the scope expands. The use case crosses system boundaries. The agent needs to reason across your ERP, your CLM, supplier portals, and years of institutional knowledge buried in email threads and approval patterns. It needs to keep working after a supplier changes their invoice format or a business unit restructures overnight.
That's a fundamentally different problem. The technical foundation to reason across a fragmented procurement stack, reliably enough to process financial transactions without a human in the loop, takes years of specialized R&D. The models were never the hard part. The context layer underneath them was.
That's what we built Fragment to do. If you're weighing this decision right now, we'll show you what autonomous exception resolution looks like on your actual data.