Three months ago, Foundation Capital made the argument that enterprises have an unsolved knowledge problem: the human judgment behind decisions made in Slack threads, Zoom transcripts, and people's heads is "never captured" and therefore cannot be learned by AI agents.
In sales, a VP might approve a discount from a Slack DM based on gut feel about the relationship. In customer support, an experienced lead might escalate a ticket based on a pattern they've internalized over years. In these (front office) domains, enterprise workflows are intentionally structured to include this type of human judgment – if you want an AI agent to replicate the behavior, it will need to replicate the human judgment. The idea is that, if you capture decision traces, AI agents can use them to replicate that human judgment.
The reaction from the community was strong. Dharmesh Shah called it "elegant" and "inevitable." Aaron Levie endorsed it. Glean's CEO said context graphs "finally had a name." A16Z published their own take. Bessemer and Greylock backed a $54M startup built explicitly around the concept. Within 90 days, Gartner predicted that 50% of AI agent systems would leverage context graphs by 2028.
The discourse was compelling, but it treated "never captured" knowledge as if it's a universal condition across all enterprise domains.
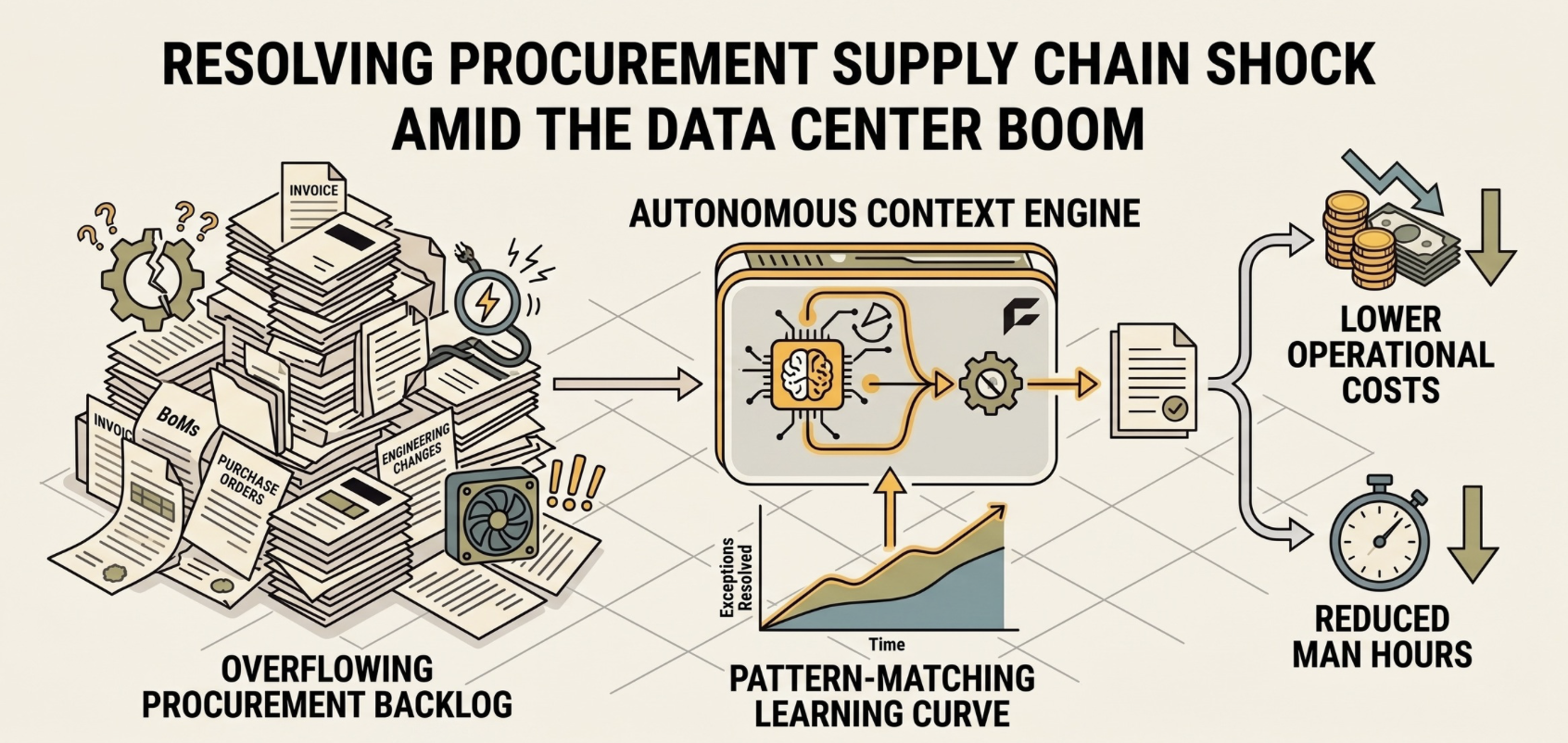
The gap I see is within operational back office domains: procurement, accounts payable, financial close, supply chain, compliance, etc. In back office workflows, knowledge is structured differently than in front office workflows, and human judgment plays a different role. The entire direct procurement function is built on documented processes specifically because every action has financial and compliance consequences.
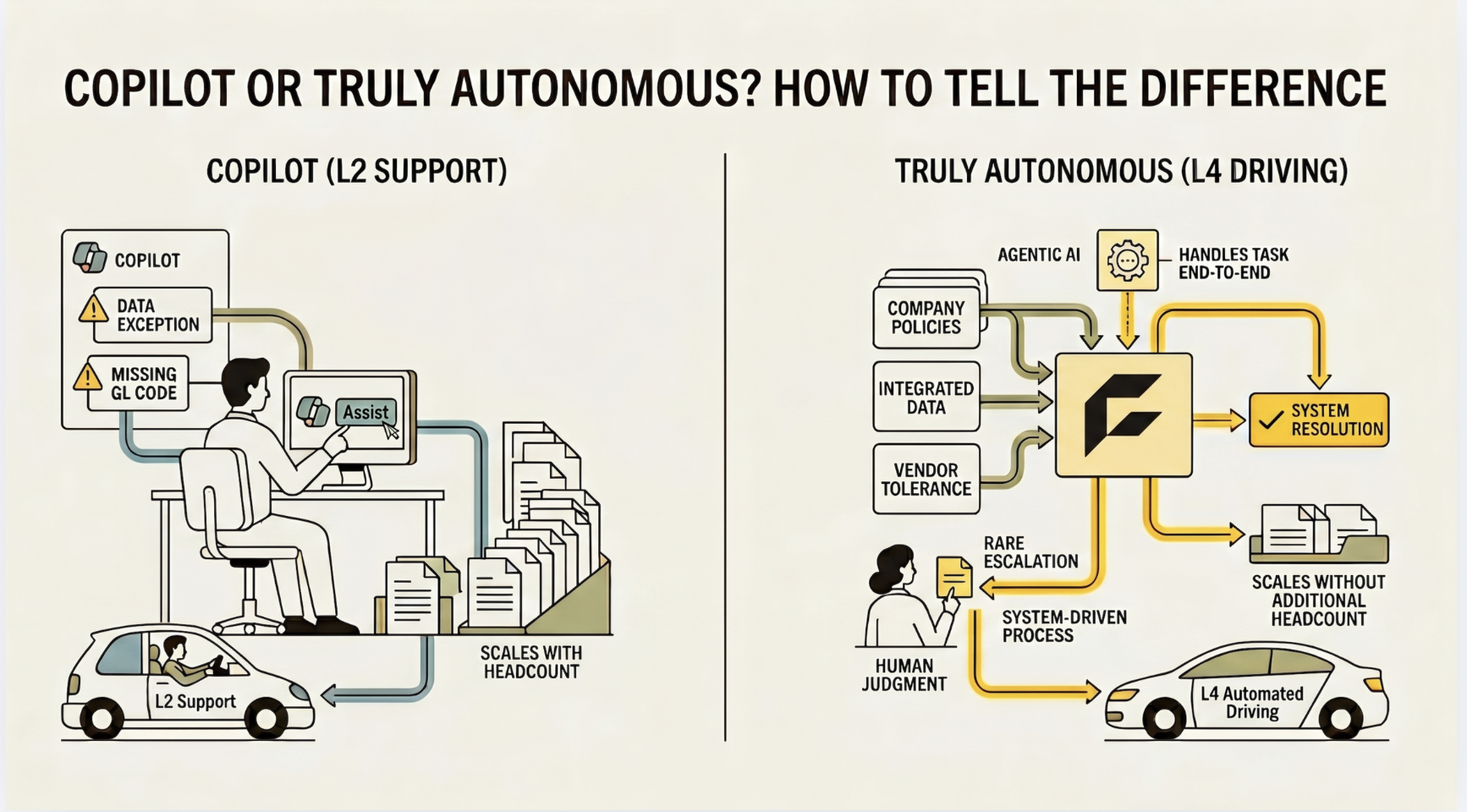
Three-way matching isn't tribal knowledge, it's a codified procedure with defined tolerances. GL coding rules aren't in someone's head, they're in the ERP configuration. Tolerance thresholds are in the AP policy. Escalation paths are in the workflow rules. Contract terms are in the CLM system. Vendor payment terms are in the master vendor record.
Even the exceptions have structure: a price variance over 5% triggers a review, a PO amendment above a dollar threshold requires re-approval.
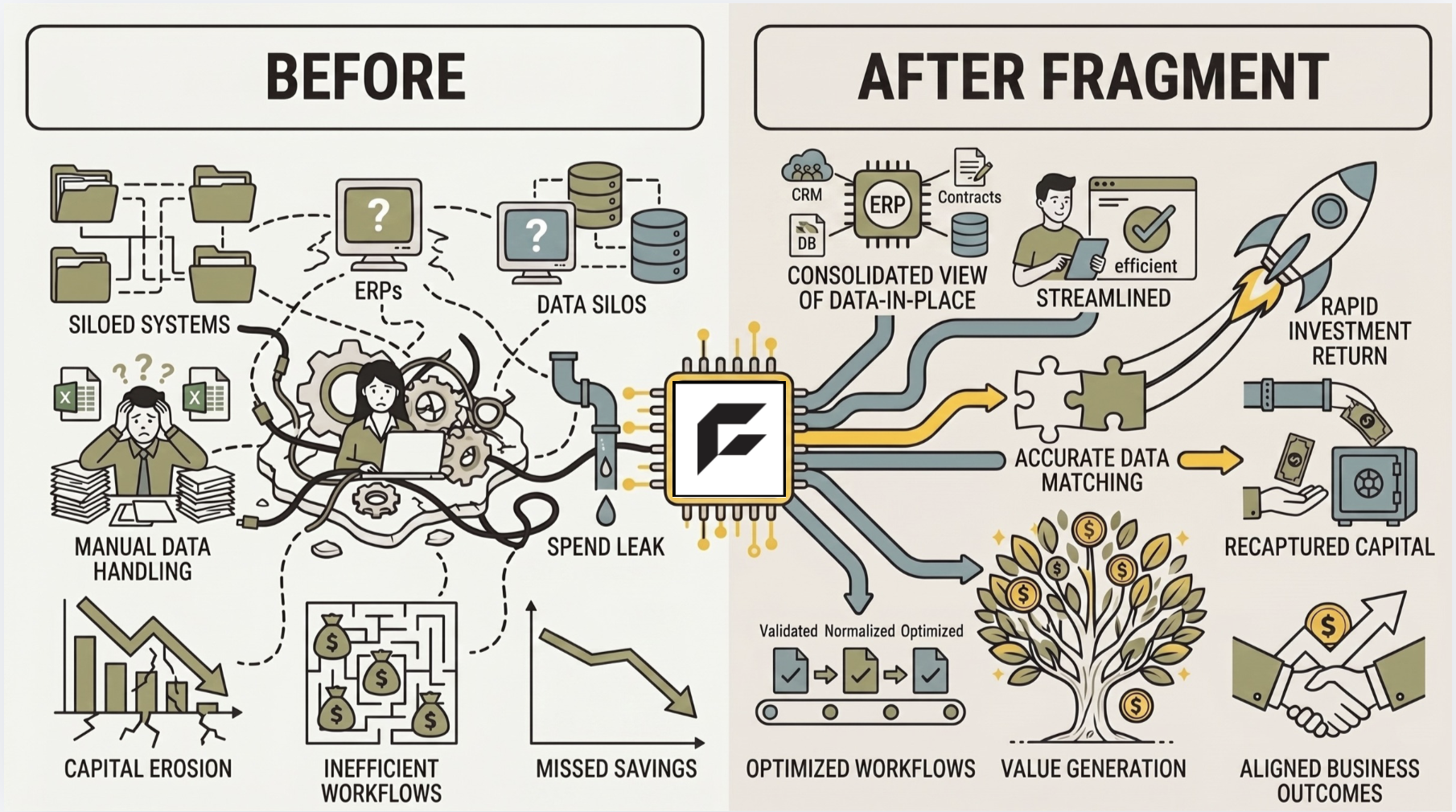
These aren't gray areas designed for human judgment. They're documented decision trees with critical knowledge distributed across the ERP, the contract management system, the supplier portal, the AP workflow tool, and the compliance framework. AI agents don't need a context graph to capture the decisions, they need an engine that can inform decision-making across fragmented systems that were never designed to work together.
The reason exceptions in procurement workflows are expensive isn't that nobody knows the resolution logic. It's that executing the logic requires a human to context-switch across systems, hold intermediate state in their head, make sequential queries against different databases, and apply conditional branching that depends on outputs from earlier steps. Every individual step in that sequence involves structured data and well-defined logic. The human judgment is in the orchestration.
Off-contract purchase orders should always be rejected but the services contract was negotiated to include a carve-out relevant to this particular order so the next action should be to contact the buyer for additional context before making this decision.
This isn't to say that "never captured" knowledge doesn't exist within back office domains, but it is narrow and specific. A particular supplier may send invoices with PO numbers in a slightly different format. Or a cost center was reorganized last quarter and the GL mapping hasn't been updated yet. That knowledge may exist only in experienced employees' heads and it's the reason why the context layer must also continuously accept human feedback and knowledge sharing. But it constitutes a thin layer on top of a deep stack of structured, codified process knowledge.
The question every builder in enterprise AI should be asking about their domain isn't simply "how do we capture "never captured" knowledge?" It's actually a precursory question: is the knowledge actually missing, or is it just fragmented?
Because the answer determines whether you need to build a context graph or a context engine, and those are very different products.